The agent had been running for forty minutes on a straightforward task: refactor the authentication module, write tests, open a PR.
By minute twelve, it had drifted — not dramatically. It still produced code, ran the test suite, committed incrementally. But the spec called for an architecture review before touching the token validation logic. The agent skipped it, not because it decided to, but because it moved to the next plausible step. That is what the model does.
By minute forty, the test suite was passing. The authentication module had been refactored in a way that was syntactically correct, functionally coherent, and architecturally incompatible with the planned microservices migration. The errors had compounded quietly across every commit, each one optimizing for the current state rather than the intended one.
This is agentic drift. It is not a model quality problem but a structural consequence of asking a probabilistic system to manage its own workflow — and it compounds the longer the session runs.
When you ask your agent how to mitigate that risk, it will suggest writing better instructions. Add emphasis. Make the constraint louder. I have done this. The system prompt began accumulating things like
IMPORTANT: DO NOT proceed to implementation before the architecture review is complete.
YOU MUST ASK THE USER TO CONFIRM FIRST!!
All caps. Exclamation marks. The model read those instructions with the same probabilistic attention it applied to everything else in the context window. Sometimes it complied. Under a long context with competing signals, it did not. The instructions had weight — not authority.
Why Agents Drift
The underlying mechanism is how attention works. Models do not process context uniformly — tokens at the beginning and end of the context window receive systematically more weight than those in the middle.1 Recency is a further pull: the closer a token is to the current generation point, the stronger its influence on the next prediction. This means a constraint written in the system prompt does not get read once and retained. It competes continuously against everything that has accumulated between it and the current step — and that competition is structural, not a failure of model quality.
Session length is the practical consequence. The longer the session, the more tool outputs, intermediate results, and generated content accumulate between early instructions and the current generation point. A constraint established in the first ten minutes may have no practical weight by minute sixty — not because the agent decided to ignore it, but because it has been progressively outweighed by more recent material.
Phase discipline breaks down for the same reason. A workflow that requires design before planning before implementation is a sequence of commitments. In a human workflow, something enforces those commitments: a ticket system, a review gate, a process that withholds the next step until the previous one is signed off. In an agent workflow that exists only as instructions in a prompt, the mechanism is the model’s compliance with those instructions. Compliance is probabilistic. Under pressure — a long context, a complex task, conflicting signals — it degrades.
The third factor is stochastic divergence. Run the same agentic workflow twice with identical inputs and you will not get identical outputs. This is expected — it is not a defect. But it means that any workflow property you rely on is a statistical tendency, not a guarantee. The agent will usually check architecture constraints. It will usually run linting before committing. Under the load of a long context or an unlucky sampling path, it won’t.
And the compounding dynamic in long sessions makes this worse: a small drift in step three becomes a larger constraint violation in step seven, because subsequent steps optimize for the current state — however that state was arrived at. By the end of a multi-hour session, the distance between what was intended and what was produced can be substantial, even though every individual step looked plausible.2
The Architecture That Should Work
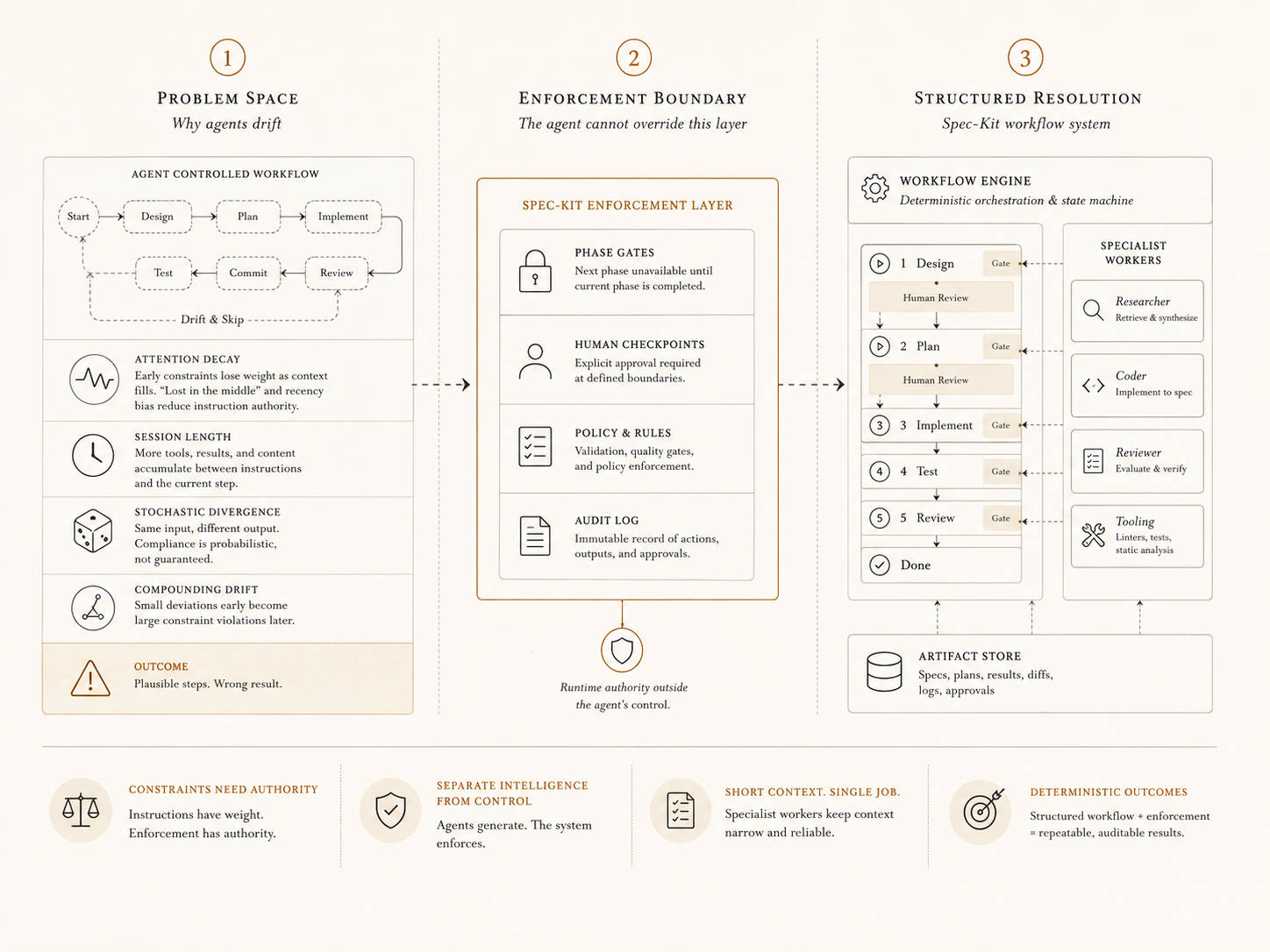
The obvious engineering response follows directly from the drift diagnosis: if an agent drifts because it carries too much — too many phases, too many concerns, too long a session — the fix is to narrow its scope. Give each agent exactly one job. A researcher that only retrieves and summarizes. A coder that only implements a bounded task against a given spec. A reviewer that only evaluates output against defined criteria. Each worker has a short context, a single responsibility, and only the tools that responsibility requires.
This is the specialist-worker architecture. The researcher receives a question and returns structured findings. The coder receives a spec and a file list and returns a diff. The reviewer receives code and acceptance criteria and returns a pass/fail with notes. The context window for each call stays narrow. The drift surface shrinks proportionally. Each invocation is short enough that recency effects and the “lost in the middle” problem don’t dominate. On paper, the architecture solves the problem that the single-agent approach could not.
But the workers don’t coordinate themselves. Something has to decide which worker runs next, what output gets passed as input to the following step, whether the reviewer’s rejection means retry or abort. The natural answer — the answer most teams reach — is to handle coordination with another agent. An orchestrator that receives the original goal, maintains the overall plan, dispatches workers in sequence, and synthesizes their outputs into a coherent result. It is a reasonable design. It is also the point where the original problem re-enters the system.
The orchestrator is an agent. It is subject to exactly the same attention mechanics established above. Its context window accumulates the outputs of every worker it has dispatched — research summaries, generated diffs, reviewer notes. Early decisions recede into the middle of a growing context: the architectural constraints agreed on at the start of the session, the scope boundaries defined before any code was written. The orchestrator’s judgment about what the reviewer’s output means, whether a failed test warrants a retry or a replanning, which worker should handle an unexpected edge case — all of that is probabilistic inference against a context that degrades over time. The specialist workers reduced drift at the leaf level. The orchestrator reintroduces it at the root.
The underlying assumption is that the orchestrator manages state coherently across the full session. In a short session with a tightly scoped task, this holds. Scale either dimension — session length or task complexity — and the assumption breaks for the same reasons it broke with the single agent.
Structure Cannot Live Inside the Agent
The structural issue is straightforward: a deterministic property cannot be achieved through a probabilistic mechanism.
Software engineering requires determinism in specific places. A function call either succeeds or raises an exception. An API contract is met or it is not. A test passes or it fails. These are not approximations. They are boolean facts on which the rest of the system depends. When an agent is asked to guarantee that planning was completed before implementation began, the guarantee is only as strong as the model’s disposition to comply.
Matthew Thompson’s Dual-State Agent Process framework formalizes this as a separation between two state spaces.3 The first is $S_{workflow}$: the deterministic control flow — what states are legal, what transitions are permitted, what happens when a guard condition fails. The second is $S_{env}$: the stochastic environment where content is generated. These are fundamentally different concerns. $S_{env}$ is where the agent operates, and probabilistic behavior is appropriate there — that is the space where language model capabilities are relevant. $S_{workflow}$ must be engineered, not modeled.
Post-condition guards follow from this separation. Instead of trusting the agent to self-certify that a phase is complete, a deterministic guard function evaluates the output against defined criteria before the workflow advances. The agent produces content; the runtime decides what happens next based on those criteria, not on the agent’s self-assessment.
There is a cost beyond correctness when this separation is absent. Without enforced state, every agent call must carry enough workflow context for the model to orient itself: current phase, completed phases, applicable rules, transition criteria. It all goes into the system prompt. With a workflow state machine managing transitions externally, each call receives only the instructions scoped to the current state. The context is narrower, cheaper, and less susceptible to instruction decay toward the end of a long window.
You cannot make an agent more deterministic by giving it better instructions. Instructions are processed by the same probabilistic mechanism that causes drift in the first place. The only way to enforce workflow structure is to move it outside the agent entirely — into an execution environment the agent cannot override.
Engineering Already Has a Framework for This
The software development lifecycle is a system of enforced handoffs, not a set of recommendations. Decades of practice produced explicit gates because teams learned that advancing on a broken foundation compounds errors faster than fixing them early.
Those gates take two forms. Phase gates control sequencing: Scrum’s Definition of Ready means a requirement cannot enter a sprint until it is specified well enough to be implemented. Large changes must be designed and decomposed into tasks before implementation begins. No skipping, no self-certification. Quality gates control output: the CI pipeline does not ask the developer whether the code is correct — it runs the tests, evaluates the result, and either blocks the merge or allows it. The developer’s intent is not a factor. The outcome is a fact.
Agents need the same structure, for the same reasons. An agent is a capable, generative worker — exactly the kind of worker you want inside a well-defined pipeline. But it should not be the pipeline. It should not decide when phases transition, whether its own output met the required criteria, or how many iterations a loop should run. Those are runtime properties. A human team enforces them with process and tooling. An agentic system needs the same enforcement — built into the execution environment, not requested of the model.
The agentic workflow engine is the piece that most implementations are missing. It is what makes the rest of the architecture coherent.
Spec-Kit: Specification as the Primary Artifact
GitHub’s Spec-Kit is an open-source toolkit for spec-driven development with AI. The central premise is straightforward: before an agent writes code, it should produce a formal specification of what it intends to build — and that specification should be reviewed and agreed on before implementation begins. The spec is not documentation added after the fact. It is the primary artifact from which everything downstream — the plan, the task list, the implementation — is derived.
The toolkit structures agentic work into four sequential phases. Specify produces a written statement of intent: what is being built and why. Plan translates that into a technical approach: how it will be built. Tasks decomposes the plan into atomic, implementable units. Implement executes them. Each phase produces a distinct artifact; each artifact is the input to the next phase. A constitution file sits alongside the phases as a persistent layer of project-level constraints — architecture rules, naming conventions, boundaries the agent must not cross — that applies across all phases without being re-stated in every prompt.
Each phase is invoked through a scoped slash command — /specify, /plan, /tasks, /implement. These are not free-text prompts. They are predefined agent instructions, each loading only the context relevant to that phase. The agent handling /plan knows it is planning — it does not carry the implementation instructions, the testing criteria, or anything outside its current responsibility. The cognitive surface is narrow by design: the same principle as the specialist workers described earlier, applied at the phase level rather than the system level.
Each phase writes its output as a Markdown file in the .specify/ directory: spec.md, plan.md, tasks.md. These are human-readable artifacts — not opaque database entries, not serialized agent state. The spec can be opened, edited, and approved before the next phase begins. When /plan runs, it receives spec.md and the constitution as its input. When /tasks runs, it receives plan.md. Each phase call is a bounded, stateless invocation against a concrete file. The continuity between phases lives in the files, not in the agent’s memory. specify init sets up the directory structure and installs the built-in workflow automatically.
The phase structure is recognizable. It is the SDLC logic from the previous chapter applied to agentic work: separate concerns, produce verifiable artifacts, advance only when the previous step is complete. At the time of the earlier article on Spec-Kit, this structure was well-designed and clearly documented. What it lacked was enforcement. The phases were a convention the agent was expected to follow — not a sequence the runtime controlled. Nothing prevented an agent from skipping directly to implementation. That is the gap the workflow engine was built to close.
Spec-Kit’s Workflow Engine
A few weeks ago I published a re-evaluation of Spec-Kit.4 Shortly after it went out, one of the maintainers reached out — and pointed me to the workflow engine that had just shipped.5 It addressed the enforcement gap described above.
The architecture is straight forward: a workflow is a YAML file with a defined schema. The runtime is a deterministic orchestrator that reads the YAML, executes steps in sequence, and dispatches AI integrations as needed. The AI calls are one step type among several. The orchestrator delegates a bounded task, collects the output, and decides what happens next.
Step types define the vocabulary:
| Type | Purpose |
|---|---|
command |
Invokes a Spec-Kit command (e.g., speckit.plan) |
gate |
Pauses for human review; on_reject: abort halts the workflow |
shell |
Executes shell commands without involving an agent |
prompt |
Sends a free-form prompt to the configured AI integration |
if / switch |
Conditional branching based on step outputs |
while / do-while |
Loops while a condition evaluates to true; max_iterations sets a hard upper bound |
fan-out |
Dispatches a step for each item in a collection; max_concurrency controls parallelism |
fan-in |
Collects all fan-out branches before proceeding |
The gate step is how the human-in-the-loop checkpoint is implemented (workflow.yml):
- id: review-spec
type: gate
message: "Review the generated spec before planning."
options: [approve, reject]
on_reject: abort
When the workflow reaches a gate step, execution pauses. The runtime checks whether it is connected to an interactive terminal (sys.stdin.isatty()). If it is, the gate prints its message, lists the options, and waits for input — approve or reject. Choosing reject triggers on_reject: abort and halts the run. If there is no TTY, there is no prompt. The step records its paused state to disk and the process exits. The run can be resumed later with specify workflow resume <run-id>. The same checkpoint works in CI without workflow changes — an adapter can bridge the paused run to any review channel, and the runtime accepts resume regardless of how the reviewer was reached. In neither path does the model participate. The checkpoint is between the human and the runtime.7
The shell step makes the separation concrete in a different way (workflow-from-file.yml):
# Spec-Kit currently lacks native file-reference inputs,
# so reading a file into the workflow requires a shell step.
- id: load-spec
type: shell
run: "cat \"{{ inputs.spec_file }}\""
A shell step runs entirely outside the AI integration. The runtime executes it, captures the stdout, and makes it available as steps.load-spec.output.stdout — a concrete string that every downstream speckit.* command receives as its input. The agent at the next step gets text, not a file path it has to resolve. It has no knowledge of whether that text came from a file, an inline argument, or any other source. The runtime resolved the value before the AI call was made.
The do-while loop shows how the same runtime authority applies to iteration (workflow.yml):
- id: review-fix-loop
type: do-while
max_iterations: 3
condition: "{{ steps.check-verdict.output.choice == 'fix' }}"
steps:
- id: code-review
command: speckit.code-review.review
integration: "{{ inputs.integration }}"
input:
args: "{{ inputs.spec }}"
- id: check-verdict
type: gate
message: "Open the feature directory's review.md, then decide: approve (done) or fix (run a fix pass)."
options: [approve, fix]
on_reject: abort
- id: fix-implementation
type: if
condition: "{{ steps.check-verdict.output.choice == 'fix' }}"
then:
- id: fix
command: speckit.code-review.fix
integration: "{{ inputs.integration }}"
input:
args: "{{ inputs.spec }}"
Three constraints govern this loop deterministically:
max_iterations: 3sets a hard ceiling. The loop cannot exceed three passes regardless of what happens inside it.- The continuation condition evaluates a human verdict. The loop continues only when the reviewer chooses
fix; choosingapproveends it. - The
if/thendispatches the fix pass only on afixverdict. On an approval, the fix step does not run.
Expressions pass typed data between steps. {{ steps.specify.output.file }} routes a previous step’s output as the next step’s input. Branching conditions like {{ steps.plan.output.task_count > 5 }} are evaluated against concrete step outputs. The expression language is a custom Jinja2-like engine with a deliberately narrow feature set: dot-path access, comparisons, boolean logic, and four filters (default, join, contains, map).
Multi-integration dispatch allows different AI models per step. The integration field is per-step configuration — a research step and an implementation step can use different models. The workflow declares this; each model at its step has no knowledge of what model ran before or will run after. The cognitive specialization is explicit in the configuration, not emergent from agent coordination.
State persistence ties the whole design together. Every workflow run stores its state under .specify/workflows/runs/<run-id>/: a state.json with the current step index and all step outputs, an inputs.json with resolved input values, and a log.jsonl append-only execution log. A paused run — whether paused at a gate or failed mid-execution — can be resumed exactly at the last completed step.6
This is what the Dual-State separation looks like in practice. $S_{workflow}$ is the YAML definition plus the runtime’s execution state. $S_{env}$ is what happens inside each AI step. The two spaces are explicitly bounded, with no leakage in either direction.
Quality gates as workflow steps extend the same principle. The shell step that loads a file above uses deterministic execution for plumbing. The same mechanism applies to verification: any check the team already runs in CI can be embedded as a workflow step, enforced before the agent proceeds.
- A test suite either passes or fails.
- A linter either reports violations or it does not.
- ArchUnit9 validates architecture rules against compiled bytecode – package dependency constraints, cycle detection, access restrictions.
These are boolean outcomes. They do not require interpretation, and they do not benefit from an agent’s judgment. They are exactly the kind of check that belongs in the runtime, not delegated to the model.
In a conventional SDLC, the CI pipeline runs these checks after code is written. The workflow engine moves them inside the agentic pipeline. A shell step that runs ./gradlew test after the implement step produces a concrete exit code. An if condition branches on that result: pass continues to the next phase, fail routes back to a fix loop or aborts. The agent never sees the test output as context to interpret. The runtime evaluates it and decides.
This is the quality gate from the SDLC analogy, made executable. The CI pipeline does not ask the developer whether the code is correct. The test suite should not be a suggestion in the system prompt. It should be a step the agent cannot skip.
Getting Started
A workflow run starts with a single command:
specify workflow run speckit -i spec="Build a kanban board with drag-and-drop"
The built-in speckit workflow runs the full SDD cycle: specify → gate → plan → gate → tasks → implement, with two human review checkpoints before any code is written. A paused workflow resumes with specify workflow resume <run-id>.
Additional workflows are distributed through the catalog system. specify workflow add <source> installs a workflow from a URL, local file, or catalog entry. The catalog resolves sources in priority order — environment variable, project config, user config, then the built-in defaults — which makes org-wide workflow overrides possible without touching individual project files.
A working implementation of the patterns described in this article — including an extended SDD workflow with an AI code-review step and a human verdict gate — is available at markuswondrak/spec-kit-workflows-demo.
Conclusion
The shift from asking agents to produce code toward asking them to first produce, and then execute, a formal specification is a meaningful structural improvement. Intention stated explicitly before implementation begins is more auditable, more consistent, and more aligned with how engineering teams actually want to work.
Without enforcement, though, an intention statement has the same effect as documentation: it describes what should happen but does not ensure it. Teams have always documented their intentions. A spec file does not stop an agent from skipping the planning phase, and a prompt instruction does not terminate a loop or create a checkpoint the model cannot bypass.
What the workflow engine adds is the enforcement layer. The spec is reviewed before planning begins because the gate step withholds execution. The review-fix loop terminates because the exit condition is evaluated by the runtime against a human’s explicit choice — not inferred from model output. Each AI step receives a bounded task; the runtime determines what happens next.
This separation — agents for generative work, a deterministic runtime for control flow — is what makes the overall system predictable. The model’s probabilistic nature is appropriate and useful inside each step. It is only a problem when that same probabilistic behavior is asked to manage the transitions between steps.
-
Nelson F. Liu et al., “Lost in the Middle: How Language Models Use Long Contexts,” arXiv:2307.03172, 2023. https://arxiv.org/abs/2307.03172 ↩
-
Matthew Thompson, “Managing the Stochastic: A Dual-State Agent Process Framework,” arXiv:2512.20660, 2024. https://arxiv.org/abs/2512.20660 ↩
-
Ibid. The paper formalizes the separation as $S_{workflow} \times S_{env}$, with guard functions $g: S_{workflow} \times Output \to \{pass, fail\}$ evaluated deterministically before any state transition. https://arxiv.org/abs/2512.20660 ↩
-
Markus Wondrak, “Re-evaluating GitHub’s Spec Kit: Structured SDLC Automation,” wondrax.cloud, April 2026. https://markus.wondrax.cloud/articles/spec-kit-reevaluation.html ↩
-
GitHub, “Workflow Engine — spec-kit Issue #2142,” github.com, April 2026. https://github.com/github/spec-kit/issues/2142 ↩
-
GitHub, “Workflow Reference — github/spec-kit,” github.com. https://github.com/github/spec-kit/blob/main/docs/reference/workflows.md ↩
-
GitHub, “Gate step —
GateStep(stdin TTY check),” github/spec-kit. https://github.com/github/spec-kit/blob/main/src/specify_cli/workflows/steps/gate/__init__.py State persistence and resume: Workflow System Architecture; gate and resume usage: Workflows README. ↩ -
GitHub, “Support file references for workflow inputs,” github.com, April 2026. https://github.com/github/spec-kit/issues/2405 ↩
-
TNG Technology Consulting, “ArchUnit – A Java Architecture Test Library,” github.com. https://github.com/TNG/ArchUnit ↩