I haven’t written a line of code by hand in months. What I do instead is describe systems — their behavior, their boundaries, their constraints — and watch agents translate that into working software. They coordinate across repositories, generate migration scripts, work through large codebases with a degree of continuity that would have been difficult to believe a few years ago. The machinery works. The harder question is what keeps it coherent when the scope expands: when sessions restart, when a sequence of agent calls is supposed to share a consistent model of what it is building, when the plan that made sense at the start silently becomes something else. That is what structural workflow tooling is meant to solve. And it is exactly where most implementations break down.
What most people try first is better prompting. You describe the phases in the system message, tell the agent where it is in the workflow. It holds for short, contained tasks. Anything spanning multiple subsystems or several sessions breaks. Context doesn’t survive session boundaries. Agents drift. The plan that made sense at the start becomes something else by the end, because nothing in the tooling prevents an agent from deciding planning is done and jumping straight to implementation.
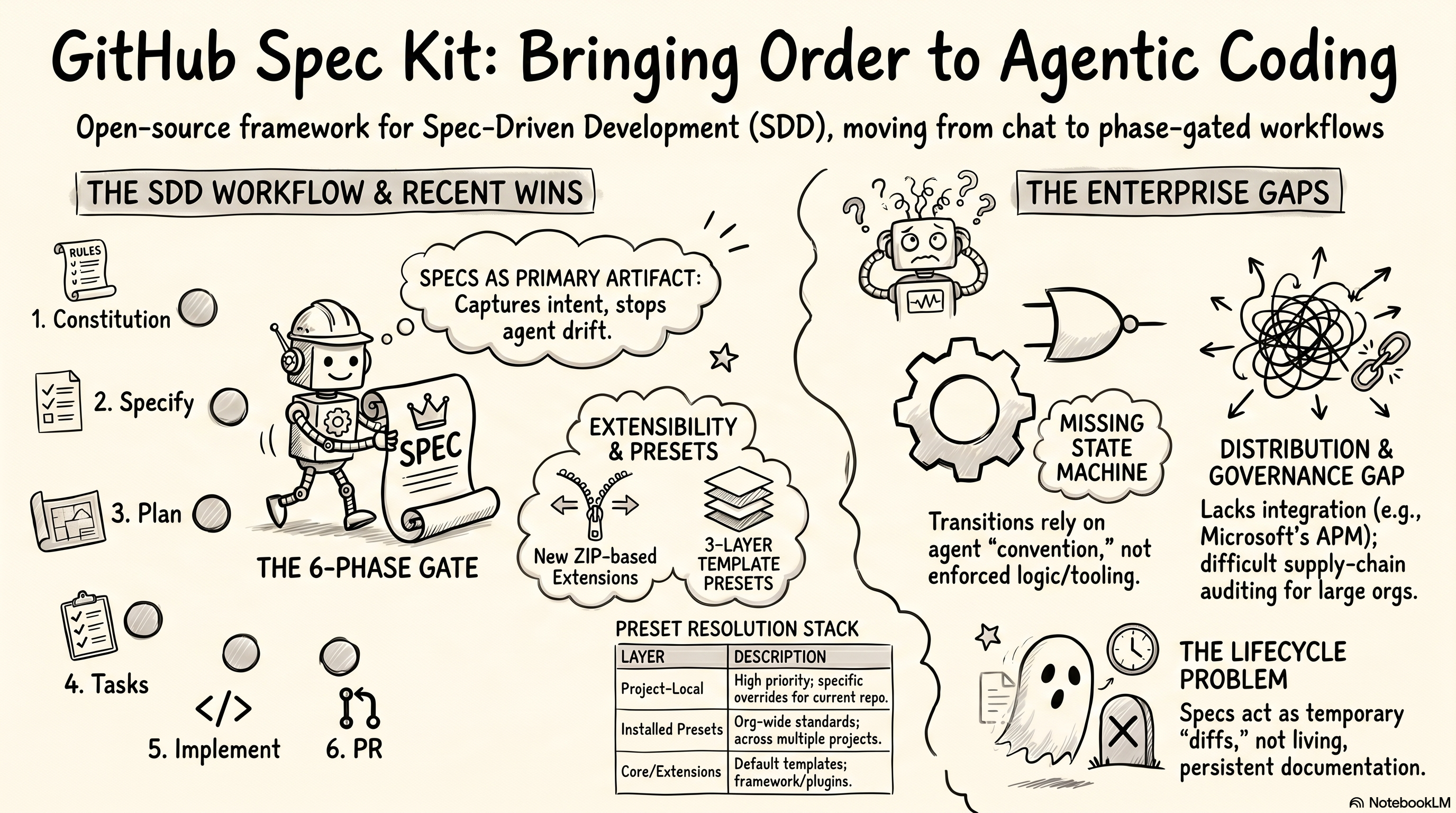
GitHub’s Spec Kit is the most visible attempt to solve this with formal structure. The idea: make the development process a sequence of defined phases, each requiring a human review before moving forward, with a formal spec as the primary artifact of the whole project.
I evaluated Spec Kit in November 2025. Let’s have a look how it developed and if we can use it in enterprise scale.
What Spec Kit Is
GitHub’s Spec Kit is an open-source framework for Spec-Driven Development (SDD). The core idea is that specifications become the primary artifact of the development process. Before any code is written, the workflow moves through structured phases:
- Constitution — define the project’s core principles and architectural constraints
- Specify — write a formal spec capturing intent, requirements, and scope
- Plan — decompose the spec into an implementation plan
- Tasks — break the plan into discrete, executable tasks
- Implement — execute the tasks using AI agents
- PR — validate, review, and merge
Each phase gates the next. As the Spec Kit authors have described it, SDD is intended as the antidote to unstructured AI coding: a way to get agents to produce reliable, intent-aligned software rather than guessing their way toward a result.1
Each gate forces the workflow to pause and verify that intent was understood correctly before moving forward. In a free-form chat session, an agent can — and often will — skip from a vague requirement directly to implementation. Here, the spec is reviewed before planning begins; the plan is reviewed before tasks are assigned. These are natural stopping points that wouldn’t otherwise exist, and in AI-assisted development they matter precisely because nothing else creates them.
Treating the spec as the primary artifact — rather than something produced after the fact — reinforces this. It forces teams to articulate what the software should do and why before addressing how. For teams working across multiple sessions or onboarding new members mid-project, the spec becomes the authoritative record of what was actually decided. Code can drift; a spec written before implementation begins is the closest thing to captured intent.
What’s Improved
The most significant changes since my original evaluation are the extension system and the separately introduced preset system. Together they make the framework considerably more adaptable to enterprise contexts.
Extensions are distributed as ZIP archives with an extension.yml manifest. Teams can define custom slash commands for agents, hook into named lifecycle points — triggering custom logic before or after any core phase — and introduce entirely new phases that aren’t part of the default workflow.2 A compliance review step, a Jira sync, or an autonomous documentation pass can be added as an extension without touching core files.
Presets address a different layer: standardizing templates and commands across teams. A preset packages overrides for specs, plans, tasks, and agent instructions with explicit priority ordering. When Spec Kit resolves a template, it walks a four-layer resolution stack — project-local overrides first, then installed presets by priority, then extension-provided templates, then core templates.8 An organization can ship a compliance or domain-specific preset once and apply it across every project without forking the repository.
These are real improvements — they extend the surface area of what teams can do with Spec Kit without modifying its core. What they do not touch is the underlying execution model. And that is where the framework’s enterprise limitations live. Three of them matter.
No State Machine
Spec Kit describes a workflow, but does not enforce one. To see why that matters, look at what the specify agent is actually instructed to do.9 Before writing a single line of spec, it must:
- check for pre-execution extension hooks and conditionally execute them
- handle branch creation
- generate the spec directory and file path
- load the correct template
- write a quality checklist to disk
After completing the spec, it must run a quality validation pass and then check for post-execution hooks. The agent is not a specification writer. It is a specification writer that also happens to be responsible for infrastructure setup, lifecycle orchestration, and quality assurance.
This is not a quirk of the specify command. It is a structural consequence of encoding runtime behavior in agent prompts. In a properly orchestrated system, lifecycle mechanics — hook execution, directory setup, state validation — are handled by the runtime before the agent is ever called. The agent receives its task cleanly scoped. Whether a hook ran is not up to the agent to interpret; the runtime executed it and passed the result. In Spec Kit, these responsibilities have been pushed into the agent’s context. The agent reads them, decides what to do with each one, and proceeds. That is a pull model: the agent interprets events rather than receiving their effects.
The same structural problem applies to phase transitions. The mechanism is Markdown files provided as context: the agent reads the current phase documentation and is expected to follow the process from there. There is no tooling that validates whether prior phases were completed, rejects invalid transitions, or signals a constraint violation.
Visual Studio Magazine’s September 2025 coverage noted that the framework requires agents to follow the process by convention rather than being constrained by the tooling.4
In my view, determinism in an agent pipeline means one specific thing: given a valid workflow state and a valid input, only valid transitions are possible, and the runtime rejects everything else. This is not a property of LLM output — it is a property of the execution environment. Spec Kit provides no such guarantee. An agent can read the spec phase, declare itself done, and proceed directly to implementation without completing planning. Nothing in the tooling prevents it.
There is a cost to the convention model beyond correctness. Without enforced state, every agent call must carry enough workflow context for the agent to orient itself: current phase, completed phases, applicable rules, transition criteria. With a state machine managing transitions externally, each call receives only the instructions scoped to the current state. The system prompt gets shorter, which means cheaper and less susceptible to instruction decay toward the end of a long context window.
The process documentation in Spec Kit is good. But for enterprise use — high-stakes changes, auditable execution, reproducible runs — documentation plus agent compliance is not a substitute for enforced state transitions. Convention breaks down under time pressure, at scale, or when agents encounter conflicting context. A state machine does not rely on compliance.
(Side note: this enforcement gap was the primary reason I built AgentMux, an orchestration pipeline built around an explicit state machine with role-scoped agent calls.)
No Distribution Layer
Spec Kit follows the standard library model: projects adopt a version, updates are available when needed, and nothing forces a change. Extensions ship as ZIP archives into .specify/, and specify extension update is the CLI command to pull in a new version — per-project, opt-in. Core workflow commands update the same way: specify init --here --force refreshes the pipeline templates, with the known caveat that --force overwrites constitution.md and requires a manual backup first.10 That is a rough edge. It is not a broken model. Libraries don’t push upgrades either.
The deeper problem is where Spec Kit as a whole fits — or doesn’t — in the ecosystem forming around agentic context engineering. Microsoft’s APM7 is the closest thing to a standard dependency manager for AI agent configuration: declare dependencies in apm.yml, lock versions in apm.lock.yaml, install with one command. It distributes instructions, skills, prompts, hooks, plugins, and MCP servers following shared conventions built on AGENTS.md, the Agent Skills specification, and the Model Context Protocol. Copilot, Claude Code, Cursor, and other agent environments can all consume the same APM package. It’s actively maintained, covers the major coding agents, and includes enterprise-grade governance tooling — policy enforcement, supply-chain auditing, org-wide version control.
Neither Spec Kit’s core framework nor its extension format maps to any of those primitives. The core framework relies on standalone CLI commands like specify init to pull templates, while an extension is a ZIP archive containing custom slash commands and phase-scoping logic. Commands like apm install spec-kit or apm install spec-kit-extension don’t exist, and not simply because no one has built the bridge. There is no schema in APM — or anywhere else — for declaring what an “agentic workflow framework” or its extensions actually are. The tooling category is real; the standard that would describe it hasn’t been defined yet.
This is the actual governance gap. When an organization adopts MCP servers through APM, policy enforcement, version pinning, supply-chain auditing, and org-wide rollout come with it. When an organization adopts Spec Kit extensions, none of that infrastructure is available — not because Spec Kit made a poor choice, but because the category it belongs to sits outside what the ecosystem has standardized. Until that changes, enterprise governance of Spec Kit deployments is a bespoke engineering problem for each team.
The first two gaps are structural — each has a clear engineering answer. The third is different. It goes to the question of what Spec Kit fundamentally believes a spec is.
The Spec Lifecycle Problem
The most significant unresolved question in the framework has been active in the community since I first evaluated the project (Discussion #152, Issue #11003).
The issue is not brownfield codebases per se — it is Spec Kit’s implicit model for what a spec is over time. Currently, each spec is essentially a diff artifact: it captures the intended change from the current state of the codebase to the desired target state. A branch is created per spec, and the spec lives for the duration of that change request. Once the feature merges, the spec becomes a historical artifact.
This is what Birgitta Böckeler, after reviewing multiple SDD tools at ThoughtWorks, classifies as spec-first — the spec is used for the task and then effectively abandoned.5 The article identifies two more advanced models: spec-anchored (the spec is retained and updated as the feature evolves) and spec-as-source (the spec is the primary artifact, with code generated from it). Böckeler observes that Spec Kit “is still what I would call spec-first only, not spec-anchored over time,” and that Discussion #152 reflects this confusion.
The problem with a pure spec-first model is that specs accumulate as a historical record without ever consolidating into a living description of what the system currently does. My own preference is to progressively integrate feature specs into a persistent product documentation layer — a maintained model of current system behavior that agents and team members can reference as a reliable source of truth. But the community has not reached consensus on this either.
Spec Kit needs to make a deliberate choice here: commit to one of these models, document it clearly, or offer explicit configuration for teams to choose their own approach. The current ambiguity leaves teams without guidance on how to manage specs over the lifetime of a project.
It is worth noting that the community has already started filling this gap. The spec-kit-archive extension6 adds a /speckit.archive.run command that runs after a PR merges, consolidating feature-level specs, plans, and technical debt notes into the project’s canonical memory at .specify/memory/. Its author describes it as the “Outer Loop” of a Double-Loop Parity model — exactly the spec-anchored direction that Discussion #152 has been asking for. That a workaround extension is needed to bridge this gap is telling in itself: it confirms both that the demand is real and that the core framework has not yet taken responsibility for it.
Conclusion
Spec Kit has matured. The extension system is a real architectural step forward, and the phase-gated workflow brings structure that free-form chat development lacks. The foundation is solid enough to build on.
The question is whether Spec Kit will own these gaps or leave them to community extensions and convention. Owning them means enforced state transitions, a distribution layer with governance, and a declared lifecycle model. That is what enterprise readiness actually requires. The direction is right. The remaining work is specific.
-
Den Delimarsky, “What’s The Deal With GitHub Spec Kit,” den.dev, 2025. https://den.dev/blog/github-spec-kit/ ↩
-
GitHub, “Extension API Reference — github/spec-kit,” github.com. https://github.com/github/spec-kit/blob/main/extensions/EXTENSION-API-REFERENCE.md ↩
-
GitHub, “Feature Request: Support Module-Level Persistent Specs,” github/spec-kit Issue #1100. https://github.com/github/spec-kit/issues/1100 ↩
-
Visual Studio Magazine, “GitHub Spec Kit Experiment: ‘A Lot of Questions’,” September 2025. https://visualstudiomagazine.com/articles/2025/09/16/github-spec-kit-experiment-a-lot-of-questions.aspx ↩
-
Birgitta Böckeler, “Understanding Spec-Driven-Development: Kiro, spec-kit, and Tessl,” martinfowler.com, October 2025. https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html ↩
-
Stanislav Deviatov, “spec-kit-archive,” GitHub, 2025. https://github.com/stn1slv/spec-kit-archive ↩
-
Microsoft, “APM — Dependency Manager for AI Agent Configuration,” GitHub, 2025. https://github.com/microsoft/apm ↩
-
GitHub, “Preset System Architecture — github/spec-kit,” github.com. https://github.com/github/spec-kit/blob/main/presets/ARCHITECTURE.md ↩
-
GitHub, “specify command — github/spec-kit,” github.com. https://github.com/github/spec-kit/blob/main/templates/commands/specify.md ↩
-
GitHub, “Upgrade Guide — github/spec-kit,” github.com. https://github.com/github/spec-kit/blob/main/docs/upgrade.md ↩