I was adding a new feature to BriefCheck: new users should get a month of premium access for free after onboarding. The change touches subscription state, trial periods, upgrade paths, and billing edge cases. The domain language matters. Does “free month” mean a trial that expires, or a grant that converts? Is the user a “trial user” or a “premium user on a promotional period”? Getting the terminology wrong cascades into wrong code. I needed a way to keep the domain model in front of the agent while we worked through the implementation.
I had read about Matt Pocock’s grill-with-docs skill and wanted to try it for exactly this kind of problem. The skill runs a focused interview session that stress-tests a plan against the project’s domain model, sharpens terminology when it drifts, and updates documentation inline so the clarification survives the conversation.8 It is exactly the kind of workflow discipline that keeps a context layer honest as the codebase outpaces the docs, the same friction arc42 is meant to solve, and the same reason I had already put it in place as the context layer for agents.9
This is exactly what a skill does well — and it is a useful example of what a skill actually is. grill-with-docs is not passive documentation. It is a procedural workflow packaged as context: a structured interview the model conducts against the domain model, with the project’s terminology anchored so nothing drifts. No ambiguity about state transitions, no guessing at edge cases. The workflow is still context the model reads, not code it runs. But it is doing something more active than enforcing a naming convention.8
So I had a look at the skill and found the wall immediately. It hardcodes a specific layout: the agent looks for a CONTEXT.md file at the project root, checks for a CONTEXT-MAP.md if the repo has multiple bounded contexts, finds ADRs under docs/adr/, and keeps the glossary implementation-free. My files live in different directories, under different names, with different conventions. The path assumptions are interleaved with the interview logic throughout the Markdown body.
The skill is not wrong. It is a perfectly good piece of declarative context. The problem is that static text cannot adapt to different project layouts. A skill that assumes docs/adr/ breaks in a repository that uses architecture/decisions/. This is a portability problem, not a missing language feature. The solution is not to make the skill smarter. It is to make the orchestrator responsible for bridging the gap between the skill’s abstract intent and the project’s concrete reality.
That experience made me look closer. The Agent Skills specification has achieved broad adoption by staying minimal.1 It defines what a skill is: a Markdown file with frontmatter that an orchestrator loads into context. It deliberately does not define how the orchestrator resolves, scopes, or adapts that context. That restraint made portability possible. Now the same restraint creates friction in five areas where the orchestrator contract is undefined.
What a Skill Is, and What It Is Not
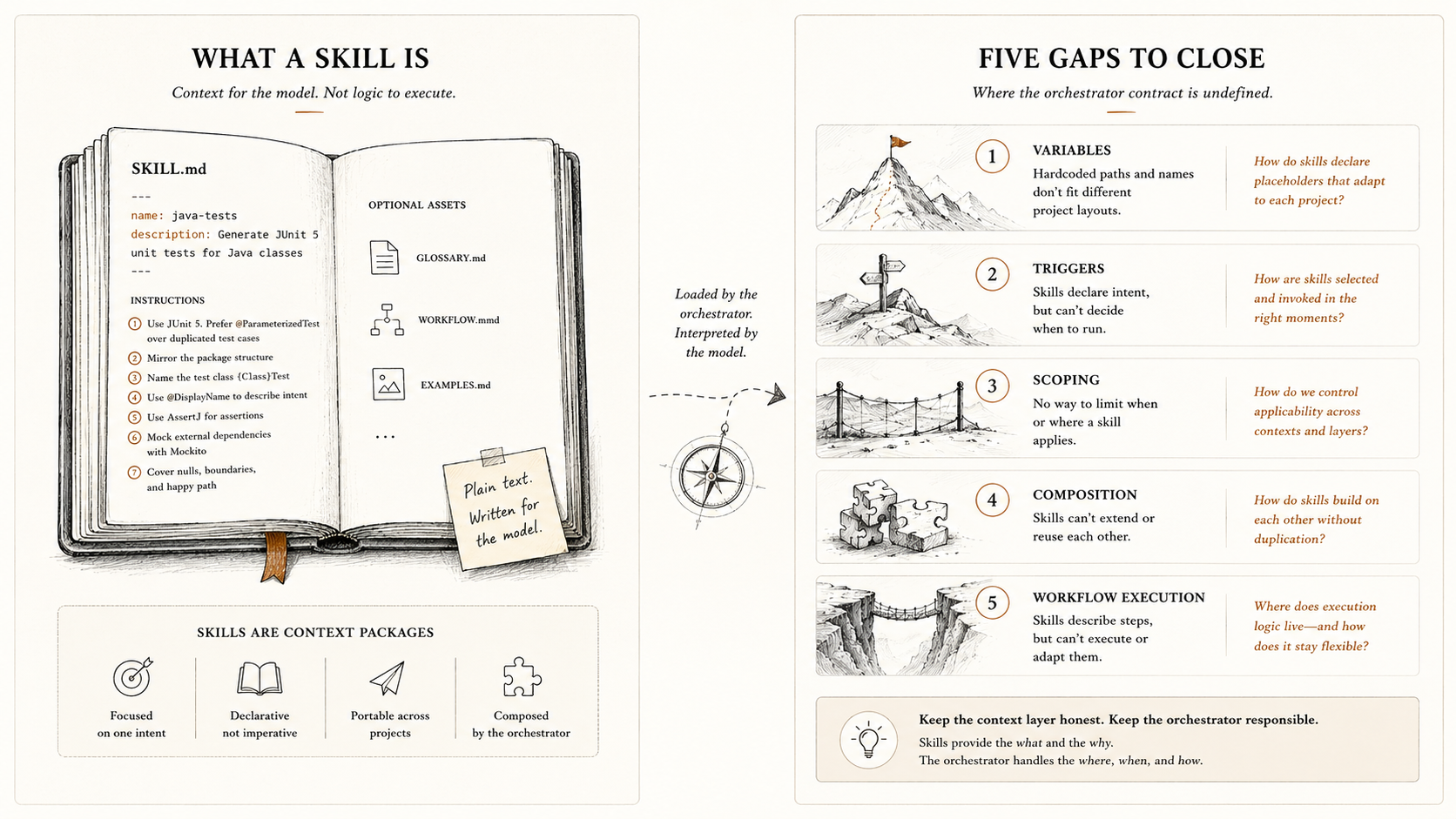
A skill has one job: give the model the right context for a specific kind of task. It is the mechanism behind grill-with-docs running a focused interview, a Java test skill enforcing JUnit 5 conventions, or a deployment skill knowing to verify rollback procedures.
On disk, it is a directory with a SKILL.md file at its root. The frontmatter declares a name and a description. The name is the skill’s identifier. The description is what the orchestrator uses to decide whether the skill is relevant to the current task.1
The body of SKILL.md contains instructions written for the model: constraints, workflow steps, style rules, or domain context. The format is Markdown. There is no special syntax for variables, conditionals, or includes. Everything the model sees is plain text that the author wrote in advance.1
A minimal skill looks like this:
---
name: java-tests
description: Generate JUnit 5 unit tests for Java classes
---
## Instructions
When asked to write tests for a Java class:
1. Use JUnit 5. Prefer `@ParameterizedTest` over duplicated test cases
2. Mirror the package structure: `src/main/java/com/example/Foo.java` -> `src/test/java/com/example/FooTest.java`
3. Name the test class `{ClassUnderTest}Test`
4. Use the `@DisplayName` annotation to describe intent in plain English
5. Use AssertJ for assertions: `assertThat(result).isEqualTo(expected)`
6. Mock external dependencies with Mockito. Do not mock value objects or internal helpers
7. Cover: null inputs, empty collections, boundary values, and the happy path
Optionally, the directory can contain additional files: image assets, Mermaid diagrams, or supplementary Markdown files. The skill may instruct the model to read these files, but the specification does not enforce how they are structured or when they are loaded.1
Skills are discovered in two ways. Global skills sit in a platform-specific directory and are available in every session. Project-local skills live inside the repository itself, typically under a hidden directory like .opencode/skills/ or .claude/skills/.2 Project skills travel with the codebase, so a team can commit its conventions to version control and every developer gets the same agent behaviour.
Activation works through progressive disclosure. At startup, the orchestrator scans all skill directories and reads only the name and description fields. The full body stays on disk. When the user submits a task, the orchestrator presents the skill descriptions to the model. The model decides which ones are relevant. Only then are the full instructions read and injected into context.1
When the model gets this wrong, the right skill is skipped — or the wrong skill is loaded and stays in context for the rest of the session.2
A skill is not code to execute, rather context to read. That context takes two forms. Some skills are declarative: rules, constraints, and terminology the model draws on as it works — a Java testing skill that enforces JUnit 5 conventions, or a domain skill that pins down what “free month” means in a subscription system. Other skills are procedural: structured workflows the model follows step by step — a grill-with-docs interview session, or a deployment skill that walks through rollback verification before releasing. Both forms are plain Markdown. Both are loaded the same way. The format makes no distinction between them, and that is appropriate: from the orchestrator’s perspective, the delivery mechanism is identical.
The mechanism is intentionally minimal: a description for matching, a body for instruction, and a directory for supporting files. That minimalism made the format portable across tools. It also leaves every question about how to resolve, scope, and merge that context unanswered — which is where the friction begins.
I identified five areas I want to address in this article:
- Template resolution. No contract for substituting externally resolved values into static skill text.
- Deterministic triggers. The model decides relevance instead of the orchestrator.
- Scope boundaries. No rule for which skills apply in which parts of a repository.
- Composition. No clean way to merge multiple skills without dependency chains.
- Workflow execution. No cross-tool standard for how the orchestrator sequences steps, manages state, and handles errors.
Each is a question the specification leaves unanswered. The first four have generated active community proposals that drift toward making the skill format more powerful rather than making the orchestrator more capable. The fifth has generated an entire ecosystem of incompatible frameworks, each one a different team’s answer to the same missing contract.
Variables: Template Placeholders, Not Runtime State
A SKILL.md file is static text. Paths, configurations, and conventions are baked into the document. If a skill needs to know where architectural decisions are recorded, it has two bad options: hardcode the path, or instruct the model to discover it.
Hardcoding breaks portability. A skill that references docs/adr/ fails in any project that uses a different layout. Instructing the model to discover the value breaks reliability. The model might search the wrong directory, skip the step, or hallucinate a path. Both options undermine the cross-product promise.
Issue #124 proposes dynamic context injection: an inline syntax where shell commands execute before the skill content is sent to the model.3 The proposal uses !`command` placeholders that the orchestrator resolves at invocation time. Claude Code already implements this exact mechanism.2
It solves the hardcoding problem directly. A skill that needs a git hash or a generated path can fetch it at invocation time instead of baking in a default. But the trade-off is architectural. Embedding shell commands inside a skill turns declarative context into an executable script. The skill now holds runtime state and side effects. It is no longer a portable document that any orchestrator can load. It is a program that requires a specific runtime.
A simpler mechanism achieves the same result without that cost. A skill should declare template placeholders that the orchestrator resolves from project metadata before the model sees the text.
---
name: grill-with-docs
description: Stress-test plans against the domain model
variables:
ADR_PATH: "docs/adr/"
CONTEXT_FILE: "CONTEXT.md"
---
## Instructions
Read the architectural decisions from {{ ADR_PATH }} and the domain glossary from {{ CONTEXT_FILE }}. Conduct an interview...
The orchestrator replaces {{ ADR_PATH }} with the actual path, resolved from project configuration. That resolution must be deterministic: the same project state always produces the same rendered text. The model receives only the rendered text. The skill itself remains stateless, side-effect free, and executable on any compliant orchestrator. The variable is not a command to run. It is a contract that says: this skill needs this piece of context, and the orchestrator must provide it.
The difference is who gathers the context. Dynamic context injection makes the skill responsible; template resolution keeps that responsibility in the orchestrator. Template placeholders solve portability, but they do not solve the question of when a skill should be loaded at all.
Triggers and Scoping: The Orchestrator Decides, Not the Model
Slash commands are deterministic. Type /java-test and the orchestrator loads that skill. No model inference, no probabilistic matching. The skill name maps directly to the file on disk.2
That pattern serves explicit user intent. The user knows which context they want and asks for it directly.
Skills are designed for a second case: context that applies automatically when the work demands it. A project-local skill committed to version control should enforce conventions without the user remembering it exists.
Automatic activation today is probabilistic. When the user does not type a slash command, the orchestrator presents skill descriptions to the model and asks it to decide which ones are relevant. Sometimes it gets this wrong. A skill with a clear description that matches the current task can still be skipped because the model weighs it against everything else in the prompt and decides to proceed without it.1
For automatic activation, the model should not guess which context it needs. The orchestrator should know.
Claude Code addresses this with a paths field in the frontmatter: glob patterns that limit when a skill is activated.2 Set paths: ["*.dart"] and Claude Code loads the skill automatically when working with Dart files. This is a deterministic trigger. The orchestrator matches the file pattern and injects the skill.
The Agent Skills specification does not define this mechanism. Claude Code implements it as a client-specific extension, which means the same paths field is meaningless to Gemini CLI, OpenHands, or any other tool.
Portability across tools is only one dimension of the activation problem. Inside a single repository, the same lack of deterministic rules produces a different but equally painful symptom. In a monorepo, different areas have different conventions. The frontend team uses different patterns than the backend team. A code-style skill at the root cannot serve both.
Issue #115 proposes path-based, recursive skill discovery.7 Skills placed in subdirectories apply only when the agent is working in that area. Claude Code already implements a version of this: project skills load from .claude/skills/ in the starting directory and in every parent directory up to the repository root.2 This is more flexible than strict subdirectory isolation. A project can define shared conventions at the repository root and override them locally in specific areas, without duplicating the common parts.
Path-based inheritance solves the monorepo problem, but it couples skill activation to directory structure in ways that are invisible to the skill itself. A developer working in src/frontend/components/ inherits skills from four levels. Which ones apply depends on what exists at every parent directory. A skill cannot declare its own scope. Its activation is determined by where it sits on disk, not by what it claims to govern. When two skills conflict, the “deepest wins” rule resolves it, but that rule is nowhere in the skill files. The developer may not know either skill is active.
Explicit scoping in the frontmatter is the cleaner alternative:
scope: "src/frontend/**"
The orchestrator matches the scope against the current working path. No inheritance chain. No hidden skills from parent directories. The developer can see exactly which skills apply by reading the frontmatter, not by tracing the file system.
Deterministic triggers complement slash commands. The user can still invoke a skill explicitly when the context is unusual or when they want control. But for automatic activation, the orchestrator should decide what to load based on rules the skill declares, not on model inference.
Composition: The Blind Spot Nobody Named
Skills are atomic by design. A Java testing skill knows JUnit 5 conventions. A deployment skill knows rollback procedures. A domain skill knows the project’s terminology. When a task touches all three areas, the orchestrator loads all three and appends them into one prompt. The model sees a single instruction set.
Plain concatenation is the simplest possible composition strategy, and mechanically it holds up. Modern models handle large context windows well and are effective at extracting the relevant subset of instructions from a combined prompt. The bottleneck is not the concatenation. The risk is overlap: two skills in the same prompt that define the same concern.
Overlap produces two failure modes:
- Redundancy. Two skills both state a rule for the same concern, wasting context and creating ambiguity about which wording is authoritative.
- Conflict. Two skills give contradictory instructions for the same operation. The model interpolates between them, and the output is non-deterministic.
Consider a concrete case that shows the second failure mode. An agent is implementing a new REST endpoint in a Go backend that follows a strict src/ package structure. Two skills are relevant and get concatenated into the prompt:
go-http-handlers.md
“Responsibility: HTTP handlers. Place handlers in
src/api/. Use thechimux framework. On error, returnhttp.StatusInternalServerErrorwith a plain text string.”
go-error-policy.md (global project standard)
“All errors in this project are logged with structure. Every HTTP error must be returned as a JSON payload in the format
{"error": "message", "code": 500}. Use the project’s internal wrapper function for this.”
The orchestrator has done its job. Both skills matched the task and were appended together. But the model now holds two contradictory instructions for the same thing: how to return an HTTP error. Because the model is designed to be helpful rather than to fail, it does not raise a conflict. It interpolates. Sometimes the first rule wins. Sometimes the second rule wins. Sometimes the model produces a hybrid. The output is non-deterministic, and neither the developer nor the orchestrator has any record that two rules were in play. When the output is wrong, debugging means guessing which skill the model chose to follow — and why.
The fix is not a smarter concatenation strategy. It is a different way to write skills. The same task, with orthogonal skills:
arch-go-routing.md — Dimension: Structure & Framework
“Responsibility: HTTP routing. Place handler packages in
src/api/. Usechifor routing. Do not handle errors here — on failure, call the project’s standard error wrapper.”
arch-go-errors.md — Dimension: Error Handling
“Responsibility: Error handling in HTTP handlers. Use
respondWithError(w http.ResponseWriter, err error). This function accepts a standard Go error and generates the correct JSON payload{"error": "message"}automatically.”
arch-go-testing.md — Dimension: Quality Assurance
“Responsibility: Unit tests for Go. For every file in
src/api/, write a corresponding_test.gofile. Use table-driven tests exclusively. Mocks are only allowed for external calls.”
When the orchestrator concatenates these three, no overlap exists. Skill 1 defines where the file goes and how routing is structured. Skill 2 is the only rule in context that covers error handling. Skill 3 applies when a test is generated. The model has nothing to arbitrate.
The principle is the same one that makes interfaces work in object-oriented design: High Cohesion, Low Coupling. A skill must define exactly one architectural truth. The moment a skill reaches into another skill’s domain — a routing skill that specifies how to log errors, an error skill that mentions test conventions — it creates the conditions for silent conflict. The orchestrator cannot detect that conflict. It assembles text, not semantics. The simpler and more focused each individual skill is, the more reliably the agent behaves when those skills are combined.
The community has followed that instinct, but the active discussions treat composition as a distribution problem:
- Issue #100 asks how skills should depend on other skills.4
- Issue #110 proposes a
requiresfield with version validation.5 - Discussion #210 offers a full
skills.jsonmanifest and lockfile modeled onpackage.jsonandgo.mod.11 - Discussion #292 specifies skills as OCI artifacts for registry-based distribution.12
- Discussion #302 proposes PURL-based identity for lightweight packaging.13
These proposals answer how skills get onto disk. None answer whether the skills that landed there can be safely combined in a single prompt. The community has not yet distinguished distribution from design-time orthogonality. A requires field implies a directed graph: Skill A needs Skill B. But skills do not need each other. They are parallel context slices that must not overlap.
The shared-value problem — two skills referencing the same artifact path — would be already solved by template variables. Each skill declares {{ ARTIFACT_PATH }} in its frontmatter. The orchestrator resolves it from project configuration before injection. Two skills get the same value without knowing about each other.
Workflow Execution: The Protocol Stack Has a Missing Layer
A procedural skill describes a workflow. grill-with-docs says:
- conduct an interview
- stress-test the plan
- anchor the terminology
A deployment skill says:
- verify rollback procedures
- confirm the rollout window
- check the health endpoint
The instructions are written down in the skills description. The model decides what to do next.
What the skill cannot say — and what the Agent Skills specification does not define — is how those steps are executed. When the interview needs to call a documentation tool, how is that invocation structured? When one phase must complete before the next begins, who tracks that state? When the workflow reaches a step that requires human approval before proceeding, how is the pause encoded and the decision fed back in? When a step fails, what gets retried and what gets skipped?
These are orchestration questions. Three protocols now address adjacent territory at the toolchain level. MCP standardises how agents connect to tools and data sources: a JSON-RPC contract that replaces the bespoke integration code every team used to write for every external service.14 A2A defines how agents communicate with each other: task delegation, result streaming, and long-running collaboration without sharing internal state.15 Agent Skills defines how context is packaged and discovered.1
Together, these three cover tools, communication, and context. None of them covers the execution model — the control flow that uses all three.
Every team answers these questions by choosing a framework. LangGraph uses a Python graph with typed state and conditional edges. CrewAI Flows uses event-driven routing with decorators. Google ADK provides SequentialAgent, ParallelAgent, and LoopAgent primitives. The OpenAI Agents SDK makes no architectural claim — control flow is plain Python code with handoffs. Microsoft shipped Semantic Kernel, deprecated it in favour of AutoGen, then deprecated AutoGen in favour of Microsoft Agent Framework, each with its own orchestration model.
That churn is the strongest signal that no framework has reached the stability of a real standard. Anthropic’s own guidance lands in the same place: “start by using LLM APIs directly. Many patterns can be implemented in a few lines of code.”16 The advice to skip frameworks is only reasonable if no framework is yet trustworthy enough to abstract over.
The AI Engineer Foundation named the problem directly. Their Agent Protocol specification reads: “The AI agent space is young. Most developers are building agents in their own way. This creates a challenge: it’s hard to communicate with different agents since the interface is often different every time.”17 The protocol’s response — a minimal REST contract for task creation and step execution — points at the right solution but stops short of the execution semantics that actually matter: state management, branching logic, human-in-the-loop interrupts, and error recovery.
The four skill-level gaps in this article are all questions about how the orchestrator handles skills. This fifth gap is a question about the orchestrator itself. Even if template resolution, activation, scoping, and composition were fully standardised, the workflow that uses all four would still be a bespoke artefact that only runs in the tool it was built for.
That question — what a portable, deterministic execution contract for agent workflows would actually look like — deserves its own treatment.
The Orchestrator Contract: Let Skills Stay Dumb
Five gaps, one cause. Each gap exists because the specification treats the SKILL.md file as a document that must do everything itself. The community responds by asking for more features in the format: variables, conditionals, dependencies, execution hooks. That response turns skills into a scripting language and destroys the portability that made them valuable.
The correct response is the opposite. The SKILL.md format should stay as minimal as possible. It should declare what it is, what it needs, and where it applies. The orchestrator should do everything else.
- Template resolution belongs in the orchestrator because it is metadata substitution, not language generation.
- Trigger and scope belong in the orchestrator because they are pattern matching, not semantic inference.
- Composition belongs in the orchestrator because it is document assembly, not reasoning.
- Workflow execution belongs in a standardised execution contract because it is control flow, not context.
The community is not really asking for a richer skill format. It is asking for a standardised process specification that lives parallel to the skills and defines how an orchestrator resolves, scopes, merges, and validates them. That specification does not exist yet. The Agent Skills specification defines the document. It does not define the runtime.
The first specification made the right call. Minimalism enabled adoption. The second specification must define the orchestrator contract: the set of deterministic operations every compliant tool must perform before handing context to the model. Without that contract, every tool extends the standard in its own direction, and the cross-product promise erodes.
Defining that contract — and specifying what it must do for both declarative and procedural skills — is the work the community has been circling around without yet naming directly.
Sources
-
Agent Skills Specification, agentskills.io. https://agentskills.io/specification ↩↩↩↩↩↩↩
-
Anthropic, “Extend Claude with skills,” Claude Code Documentation. https://docs.anthropic.com/en/docs/claude-code/skills ↩↩↩↩↩↩
-
digitarald, “Proposal: Dynamic context injection in SKILL.md,” agentskills/agentskills Issue #124, February 6, 2026. https://github.com/agentskills/agentskills/issues/124 ↩
-
marcofranssen, “Best practice on having a skill use/depend on other skills,” agentskills/agentskills Issue #100, January 22, 2026. https://github.com/agentskills/agentskills/issues/100 ↩
-
AndoSan84, “Adding Skill Dependencies with Version Validation + Testing Specification,” agentskills/agentskills Issue #110, January 28, 2026. https://github.com/agentskills/agentskills/issues/110 ↩
-
PaulRBerg, “Clarify whether nested skills are allowed,” agentskills/agentskills Issue #137, February 12, 2026. https://github.com/agentskills/agentskills/issues/137 ↩
-
lcs-bdr, “Proposal: add path-based, recursive skill discovery,” agentskills/agentskills Issue #115, February 2, 2026. https://github.com/agentskills/agentskills/issues/115 ↩
-
Matt Pocock, “grill-with-docs” skill, mattpocock/skills repository. https://github.com/mattpocock/skills/blob/main/skills/engineering/grill-with-docs/SKILL.md ↩↩
-
Markus Wondrak, “From Wiki to Source: How arc42 Becomes the Context Layer for AI Agents,” 2026. https://wondrax.cloud/articles/documentation-agentic-coding ↩
-
Markus Wondrak, “The Agent is not the Pipeline: Spec-Kit Workflows and the Enforcement Layer,” 2026. https://wondrax.cloud/articles/deterministic-pipelines ↩
-
erdemtuna, “Proposal: Skill Package Manifest for Dependency Resolution and Distribution for Agent Skills,” agentskills/agentskills Discussion #210, March 5, 2026. https://github.com/agentskills/agentskills/discussions/210 ↩
-
ThomasVitale, “Specification for Skills Packaging and Distributions as OCI Artifacts,” agentskills/agentskills Discussion #292, March 2026. https://github.com/agentskills/agentskills/discussions/292 ↩
-
maxschulz-COL, “Proposal: Specs for Skills packaging and distribution without infrastructure overhead,” agentskills/agentskills Discussion #302, April 2026. https://github.com/agentskills/agentskills/discussions/302 ↩
-
Anthropic, “Model Context Protocol,” modelcontextprotocol.io. https://modelcontextprotocol.io ↩
-
Google et al., “Agent2Agent Protocol,” a2a-protocol.org. https://a2a-protocol.org ↩
-
Anthropic, “Building effective agents,” December 2024. https://www.anthropic.com/research/building-effective-agents ↩
-
AI Engineer Foundation, “Agent Protocol,” agentprotocol.ai. https://agentprotocol.ai ↩